KEGG is a database resource for understanding high-level functions and utilities of the biological system, such as the cell, the organism and the ecosystem, from molecular-level information, especially large-scale molecular datasets generated by genome sequencing and other high-throughput experimental technologies. A recent paper is: Molecular network analysis of diseases and drugs in KEGG. Kanehisa M. Methods Mol Biol. 2013;939:263-75. doi: 10.1007/978-1-62703-107-3_17. We are grateful to the authors for creating and curating KEGG and thank them for making the structures available via PubChem for incorporation into ZINC.
We assess the chemical diversity of a subset by clustering the molecules. First, we sort ligands by increasing molecular weight. Then, we use the SUBSET 1.0 algorithm ( Voigt JH, Bienfait B, Wang S, Nicklaus MC. JCICS, 2001, 41, 702-12) to progressively select compounds that differ from those previously selected by at least the Tanimoto cutoff, using ChemAxon default fingerprints. The resulting representatives have two interesting properties:
| Tanimoto Cutoff Level | 60% | 70% | 80% | 90% | 100% |
|---|---|---|---|---|---|
| Number of Representatives | 1,749 | 2,587 | 3,346 | 4,260 | 6,853 |
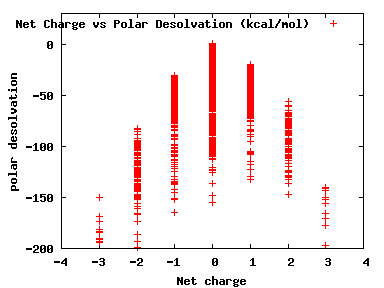
We compute the physical properties of each molecule in the subset, and graph them below.
Download Calculated Physical Properties





| Format | Reference(pH 7) | Mid(pH 6-8) | High(pH 8-9.5) | Low(pH 4.5-6) | Download Unix |
Download Windows |
|---|---|---|---|---|---|---|
| SMILES | All | All | All | All | ||
| MOL2 | All | All | All | All | Single Usual Metals All | Single Usual Metals All |
| SDF | All | All | All | All | Single Usual Metals All | Single Usual Metals All |
| Flexibase | Not Available | Not Available | Not Available | Not Available |